Efficient Log Management with Fluent Bit and Amazon S3
Efficient Log Management with Fluent Bit and Amazon S3
Observability is crucial to modern-day distributed systems due to their complexity, scale, and dynamic nature. To get a comprehensive understanding of such systems we need to have access to metrics, logs, and traces from all the components in order to help teams identify and debug issues.
Tools like Fluent Bit make it easy to collect logs metrics and traces from multiple sources and forward them to a repository. (Check out our previous post on using Fluent Bit to collect metrics from multiple sources.)
Once the data are collected, they need to be stored in a central location to help with auditing and performance enhancement.
Tools like Amazon S3 are a popular choice when it comes to cost-effective and scalable solutions to store and manage large volumes of metrics, logs, and traces. With centralized data storage, teams can more easily track and optimize performance, as well as meet compliance and auditing requirements.
In this blog post, we’ll see how we can collect and forward metrics and logs from Fluent Bit to Amazon S3.
Why Use Amazon S3 For Storing Logs?
Amazon S3 is a highly scalable, durable, and secure object storage service provided by AWS. It allows users to store and retrieve any form of data like text files, images, and videos, from anywhere on the web.
Let us look into why to use Amazon S3 for storing logs:
Scalability: Amazon S3 is a highly scalable and durable service that can store virtually unlimited amounts of data. This makes it an ideal solution for applications that generate a large volume of logs, metrics, and traces.
Cost-effective: With low storage costs and pay-as-you-go pricing, Amazon S3 is a cost-effective option. You can store and retrieve your data without worrying too much about the costs.
Easy integration: Being an AWS offering, S3 easily integrates with other AWS services, such as Amazon CloudWatch and Amazon OpenSearch Service, allowing you to collect and analyze logs, metrics, and traces in a unified way.
Secured: Amazon S3 comes with robust access control and security mechanisms built in to avoid any unauthorized access. This ensures that your data is secure and compliant with industry standards and regulations.
Data durability: Amazon S3 is highly durable and available in case of hardware failures or natural disasters. It does so by storing multiple copies of your data across multiple devices and data centers.
Analytics: S3 provides built-in analytics capabilities, such as S3 Inventory and S3 Select, that allow you to analyze your data at scale and gain insights into usage patterns, access patterns, and other metrics.
Forwarding Logs From Fluent Bit To S3
Having understood the features of Amazon S3, let us see how we can forward logs from Fluent Bit to S3. Fluent Bit comes with a setup of INPUT and OUTPUT plugins that allows it to be a versatile option for collecting logs. One of the plugins is the Amazon S3 output plugin that we’ll be using.
We’ll configure Fluent Bit to collect CPU, System, and Kernel logs from a server and push these logs to Amazon S3.
Refer to the Fluent Bit installation documentation to install it on your system.
AWS S3 Configuration
The first step here is to create an S3 bucket if you don’t already have one. Once the bucket is created, you need to ensure that the s3:PutObject IAM permission is provided. To do this, navigate to the Permissions tab for the S3 bucket and add the following code snippet under Bucket Policy.
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "*"
}]
}This basically gives allow access to add objects to the bucket.
After this, you’ll need the credentials of the AWS principal which you can create by visiting IAM -> Access Management -> Users and selecting the user. Navigate to the Security Credentials tab and generate access keys. Note down the access key and secret.
If you’re using an Ubuntu system, AWS credentials are stored at /home/<username>/.aws/credentials where you need to update these credentials. You can either edit the file here and add the following lines:
[default]
aws_access_key_id = <Access_ID>
aws_secret_access_key = <Access_Secret>The easier way is to configure AWS CLI on your system. Once configured, fire up a terminal and enter aws configure, provide the Access key and secret in the dialog that appears. This automatically saves the details to the credentials file.
Fluent Bit Configuration
Working with S3 requires Fluent Bit to connect to the S3 bucket which is only possible using credentials. To understand more about how Fluent Bit retrieves AWS credentials, read this.
Since our credentials are already updated in the .aws/credentials file, we then need to configure the service config file for Fluent Bit and set the path to this credential file – Reference. In order to do that, fire up a terminal and edit the fluent-bit.service file present at /usr/lib/systemd/system/fluent-bit.service.
You need to add the following line after [Service]:
[Service]
Environment="AWS_SHARED_CREDENTIALS_FILE=/home/<username>/.aws/credentials"After this is done, let us update the config file with INPUT and OUTPUT plugins as follows:
INPUT
[INPUT]
Name cpu
Tag fluent_bit
[INPUT]
Name kmsg
Tag fluent-bit
[INPUT]
Name systemd
Tag fluent-bitWe are taking inputs from three different sources — cpu, kernel, and systemd.
OUTPUT
[OUTPUT]
name stdout
match *
[OUTPUT]
Name s3
Match *
Bucket fluent-bit-s3-demo
Region us-west-2
Store_dir /tmp/fluent-bit/s3
Total_file_size 10MWe have two outputs here, one will write all the logs onto the screen and the other is the S3 plugin. We need to mention the name of the S3 bucket and the region where the bucket is. Please remember to update the Bucket and Region based on your setup.
We also need to specify a Store_dir which basically stores the logs for a duration before pushing it to S3. Further in situations where the fluent-bit service stops for any reason, the logs will be saved here and pushed to the S3 bucket once it restart. This ensures you don’t lose our logs.
After this is configured, save the config file and run the fluent-bit service. Navigate to the S3 bucket and you should see folders being created with the name `fluent-bit`, and within the folder, you’ll see subfolders based on year, month, date, and time and eventually the log files. You can configure this by going through the S3 output configuration parameters.
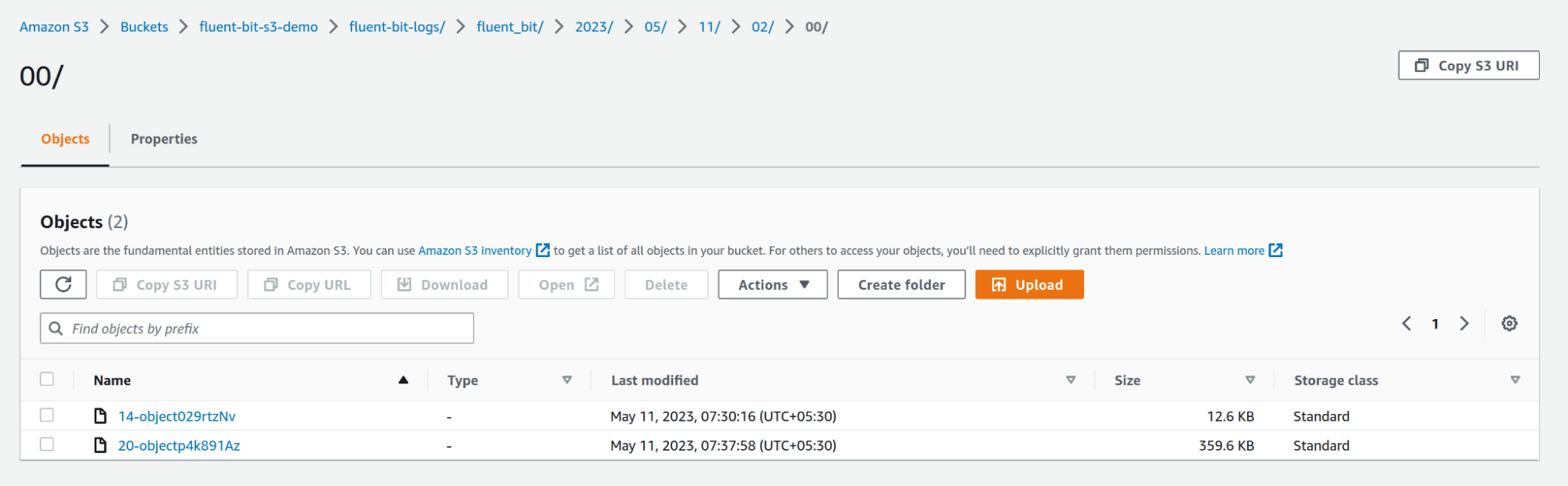
In this way, we can use Fluent Bit to collect logs, metrics, and traces from multiple sources and push them to an S3 bucket for storage and further analysis.
Summary
Metrics, logs, and traces provide valuable insights into system performance, user behavior, and potential issues. By centralizing these logs in a reliable and scalable storage solution like Amazon S3, teams can not only improve system auditing and performance but also ensure built-in security and easy integration with other AWS services.
With a tool like Calyptia Core, you can further reduce the efforts and simplify your observability efforts. It allows you to visualize and build pipelines that help you improve the quality of your data and eliminate irrelevant data.
Effective log collection and storage are critical for the success of any modern distributed system. Investing in a comprehensive log collection and storage strategy is essential for maintaining a successful and efficient distributed system.
You might also like

A practical guide for avoiding data loss and backpressure problems with Fluent Bit
Learn how to detect and avoid backpressure problems with Fluent Bit by balancing memory-based and filesystem-based buffering.

