
Fluent Bit Tips & Tricks: Agile Iteration and Simple Debugging
Fluent Bit Tips & Tricks: Agile Iteration and Simple Debugging
How to move fast and not break things
tl;dr:
If there are three massive helpers to both debugging issues or iterating/testing Fluent Bit features they are this:
Increase your debug level and never ignore warnings
Simplify your stack with stdout output
Reproduce or iterate locally with containers
This is an update to a previous blog post that offered tips and tricks for making the most of Fluent Bit for log forwarding. This new post includes new tooling and options since that one was put together. Keep your eyes peeled for more posts on further tips and tricks.
Warnings Are Errors
A good mantra to follow in all (software) life is warnings are errors. Please do not ignore them in Fluent Bit logs, and if you are having any other issues you should immediately investigate the warnings even if they seem unrelated.
A good investigative first step is always to increase your debug level, regardless of tooling, and this is simple to achieve with Fluent Bit:
[SERVICE]
Log_level debugOnce you have done this, check for debug statements indicating issues.
One particular issue that comes up often is tail not picking up files. Generally the debug log gives you some detail on this:
Quite often this is a permissions issue with Fluent Bit (or the user it is run as) not being able to access the files. The debug logs will reveal this with a log line saying something equivalent to “0 files found in this directory”. You can easily verify what the filesystem presents to Fluent Bit as the user to check.
The other thing to check on Kubernetes is for symlinks and not mounting the symlink destination. While you may have created /var/log/containers as a symlink to /var/log/pods, if you did not mount the target into the container then Fluent Bit cannot read it. The Fluent Bit debug image can be shelled in to check this as well.
Follow Your Tail
This next point is good to highlight because even though it is documented it still comes up often: the tail plugin functions by default as equivalent to tail -f.
What this means is that it will only show data added to the file since Fluent Bit started tailing it. It will not (by default) show existing content in the file. You must push new log lines to the file for Fluent Bit to pick up that data.
This is as expected and as desired: otherwise every time you restart Fluent Bit you would duplicate all your old log data already in the file, for example.
Simplify — Divide and Conquer Your Stack
With any complex system of multiple components, the first step is to identify where the issue is.
Many questions asked across our Slack, Github issues, or wherever follow the same template (insert your favourite tooling of choice below):
I have Fluent Bit plus [large set of moving parts] showing info in [visualisation tool]; it’s not showing the right information. Why?
In this case, the usual response is to simplify things to determine whether the issue is with Fluent Bit or something else further in the pipeline. The easiest way to do this is to add a stdout output plugin configuration, which will show what Fluent Bit thinks the data looks like at that point in the chain.
[OUTPUT]
Name stdout
Match *With this output set up you should then be able to confirm any issues with data format (e.g. parsing failures) or missing data.
The old ways are still the best, and this is very much tried and tested printf debugging! This tip will show exactly what Fluent Bit is doing and how the data is formatted at that point in the chain. You can add this configuration to your existing configuration without changing anything else just to see the output.
As Fluent Bit is vendor agnostic it can target a myriad of further observability tooling (Grafana, Elastic, New Relic, Splunk, Datadog, etc.) but this does bring some complexity when investigating issues. This is not all bad though; with all this flexibility you have options in both debugging issues but also pushing your data to other tools to verify if those work (if they do then likely your problem is elsewhere).
Standard Output Filter
There is also an option of adding a stdout filter within your pipeline: filters are applied in order so this is a good way to see what is happening between filter stages.
Visualization
Recently we published a post on using some of our other (free) tooling from Calyptia Cloud to verify things like regular expressions but also un-matched outputs. It’s worth a read as these are all strings to your bow to figure out why something is “not working”: Troubleshooting your Fluent Bit Configuration with Calyptia Cloud
For example, stdout output may not show any data. This could be an issue with configuration; for example, maybe your output is not matching your input (or with larger
configuration, maybe one of the outputs is not or only matching a subset of what it should).
The visualisation tool shows this very obviously.
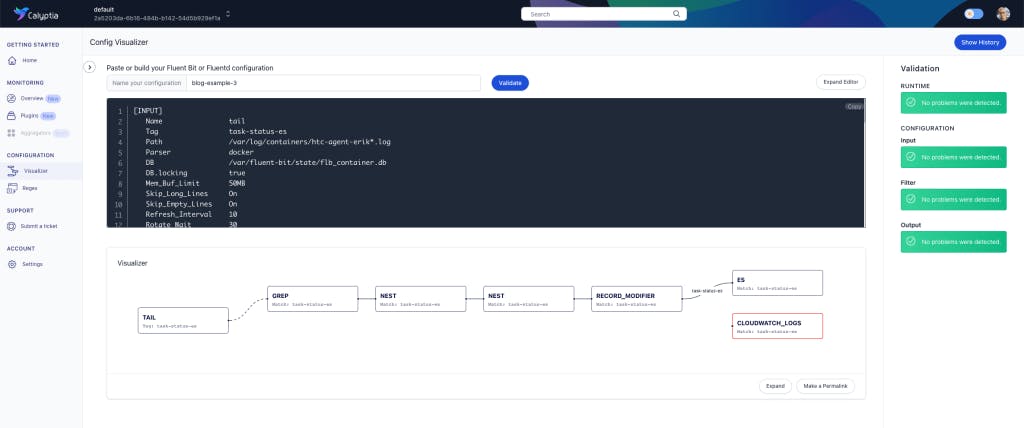
Local Iteration — Fast Turnaround Testing
One thing I would encourage everyone to do during development is make use of the ephemeral nature of containers for testing and verification. They make it trivial to test different versions or configurations, even for different Linux distributions.
Quite often, if I see an issue come up in Slack I can quickly test it locally in one of these ways:
Run the container with CLI parameters
Run the container with a local config file
Run a docker compose stack of multiple containers — generally more useful for larger examples of multiple components but a template can be reused easily
Crash-test Dummies
This approach is really useful to quickly iterate, particularly when combined with a dummy input to generate test data matching whatever specific corner case is not working.
Using an input file can be helpful particularly in CI but requires a bit more set up to get working. If you just need to test specific strings of input then dummy is a great way to do this.
As an example of running just with the CLI flags:
$ docker run --rm -it fluent/fluent-bit -i dummy -o stdout -m '*'
Fluent Bit v1.9.6
* Copyright (C) 2015-2022 The Fluent Bit Authors
* Fluent Bit is a CNCF sub-project under the umbrella of Fluentd
* https://fluentbit.io[2022/08/01 09:24:55] [ info] [fluent bit] version=1.9.6, commit=b30141ba90, pid=1
[2022/08/01 09:24:55] [ info] [storage] version=1.2.0, type=memory-only, sync=normal, checksum=disabled, max_chunks_up=128
[2022/08/01 09:24:55] [ info] [cmetrics] version=0.3.5
[2022/08/01 09:24:55] [ info] [output:stdout:stdout.0] worker #0 started
[2022/08/01 09:24:55] [ info] [sp] stream processor started
[0] dummy.0: [1659345895.557489597, {"message"=>"dummy"}]
[0] dummy.0: [1659345896.556420056, {"message"=>"dummy"}]
[0] dummy.0: [1659345897.556307786, {"message"=>"dummy"}]This shows just the default example of dummy input with stdout output matching a wildcard: one issue with using CLI flags is you may need to quote/escape special characters for your shell so the config file approach is usually my preference.
To run a container up with a local configuration file as an example, just do the following (assuming your local file name is fluent-bit.conf):
docker run --rm -it -v $PWD/fluent-bit.conf:/fluent-bit/etc/fluent-bit.conf:ro fluent/fluent-bitThis then runs up the container and mounts the local file over the top of the default configuration file. You can easily include all your configuration then very simply — make sure to mount any additional files you may need (e.g. if you include parsers or other config files then these need to be available in the container) and typically I do this via a root directory I just mount in one go then.
Recently we helped out with a specific use of rewrite_tag using the following configuration that exposes more of the power of dummy:
[INPUT]
NAME dummy
Dummy { "log": "2022-07-16 02:44:09 [main] INFO c.c.app.config.LogUtil - (()){\"type\":\"messageLog\", \"status\":\"success\", appName:\"appConfigService\""}
Tag test_log
[FILTER]
Name rewrite_tag
Match test_log
Rule $type (messageLog) tLOG true
Emitter_Name re_emitted
[OUTPUT]
Name stdout
Match *Now if we run it up we can see the combination of using dummy with stdout to show the tag:
$ docker run --rm -it -v $PWD/fluent-bit.conf:/fluent-bit/etc/fluent-bit.conf:ro fluent/fluent-bit
Fluent Bit v1.9.6
* Copyright (C) 2015-2022 The Fluent Bit Authors
* Fluent Bit is a CNCF sub-project under the umbrella of Fluentd
* https://fluentbit.io
[2022/07/20 09:05:05] [ info] [fluent bit] version=1.9.6, commit=b30141ba90, pid=1
[2022/07/20 09:05:05] [ info] [storage] version=1.2.0, type=memory-only, sync=normal, checksum=disabled, max_chunks_up=128
[2022/07/20 09:05:05] [ info] [cmetrics] version=0.3.5
[2022/07/20 09:05:05] [ info] [sp] stream processor started
[2022/07/20 09:05:05] [ info] [output:stdout:stdout.0] worker #0 started
[0] test_log: [1658307905.610239110, {"log"=>"2022-07-16 02:44:09 [main] INFO c.c.app.config.LogUtil - (()){"type":"messageLog", "status":"success", appName:"appConfigService""}]
[0] test_log: [1658307906.610228129, {"log"=>"2022-07-16 02:44:09 [main] INFO c.c.app.config.LogUtil - (()){"type":"messageLog", "status":"success", appName:"appConfigService""}]This approach can verify parsing of particular problematic strings at least initially with dummy generating them and then move it into sample input data files for full CI regression testing. It means you can quickly iterate very easily.
An additional benefit is that you then have a fully reproducible example in case you need to submit an issue or share with others in some fashion — no “magic” VMs or “it works on my machine” then.
Training Labs Sandbox
We provide various free training labs via Instruqt for Fluent Bit.
The tutorials walk you through specific examples but they can also be used as a simple sandbox environment to experiment with Fluent Bit. You can skip the training steps and just run the sandbox and edit the configuration to try things out.
OS testing
We actually use containers to do some basic smoke testing of the various Linux packages we build.
It is trivial to do a quick sanity check on a single host rather than spin up dedicated VMs for each OS: obviously you should do this as well, but you want to fail fast and early if there is a simple issue rather than waste time and money on a VM.
We added the one-line install script to Fluent Bit primarily to help support this during testing, so now you can run a test install very easily:
$ docker run --platform=linux/arm64 --pull=always --rm -it ubuntu:18.04 /bin/sh -c "apt-get update && apt-get install -y gpg sudo curl && curl https://raw.githubusercontent.com/fluent/fluent-bit/master/install.sh | sh && /opt/fluent-bit/bin/fluent-bit --dry-runThis shows an example of testing another architecture as well as distribution all together. Note the installation of sudo and curl as these are both tools used during installation — gpg is required for signed repositories as well but typically all this would be present on a “real” OS.
Now, containers cannot do everything and it gets particularly complicated with init processes although there are some options. However full package testing always should be done directly on that distro; this just provides a sanity check of things like certificates and repo data is all ok too.
Conclusion
Using the approaches shown above you should be able to diagnose most of the issues you might hit as well as test out the impact of changes or new features. This is by no means a comprehensive list and we will be providing more helpful tips, tricks, and examples.
You might also like

Fluent Bit and Fluentd – a child or a successor?
Fluent Bit may have started as a sibling to Fluentd, but it is fair to say that it has now grown up and is Fluentd's equal. Learn which is right for your needs and how they can be used together.

