3 ways to save money on Splunk with Calyptia
3 ways to save money on Splunk with Calyptia
If you go to any Fortune 100 company, you will most certainly find Splunk. Splunk gives rich analytic capabilities on top of one of the most versatile data sources (machine data, logs). Adding more data to Splunk is super easy and adds more value to the organization – whether you are in Security, Operations, Observability, or IT.
The problem with this ease of use is that adding more data can lead to a bill that blows past your budget. In this blog, we will discuss 3 ways to keep Splunk’s amazing experience by using Calyptia to save money.
What is Calyptia?

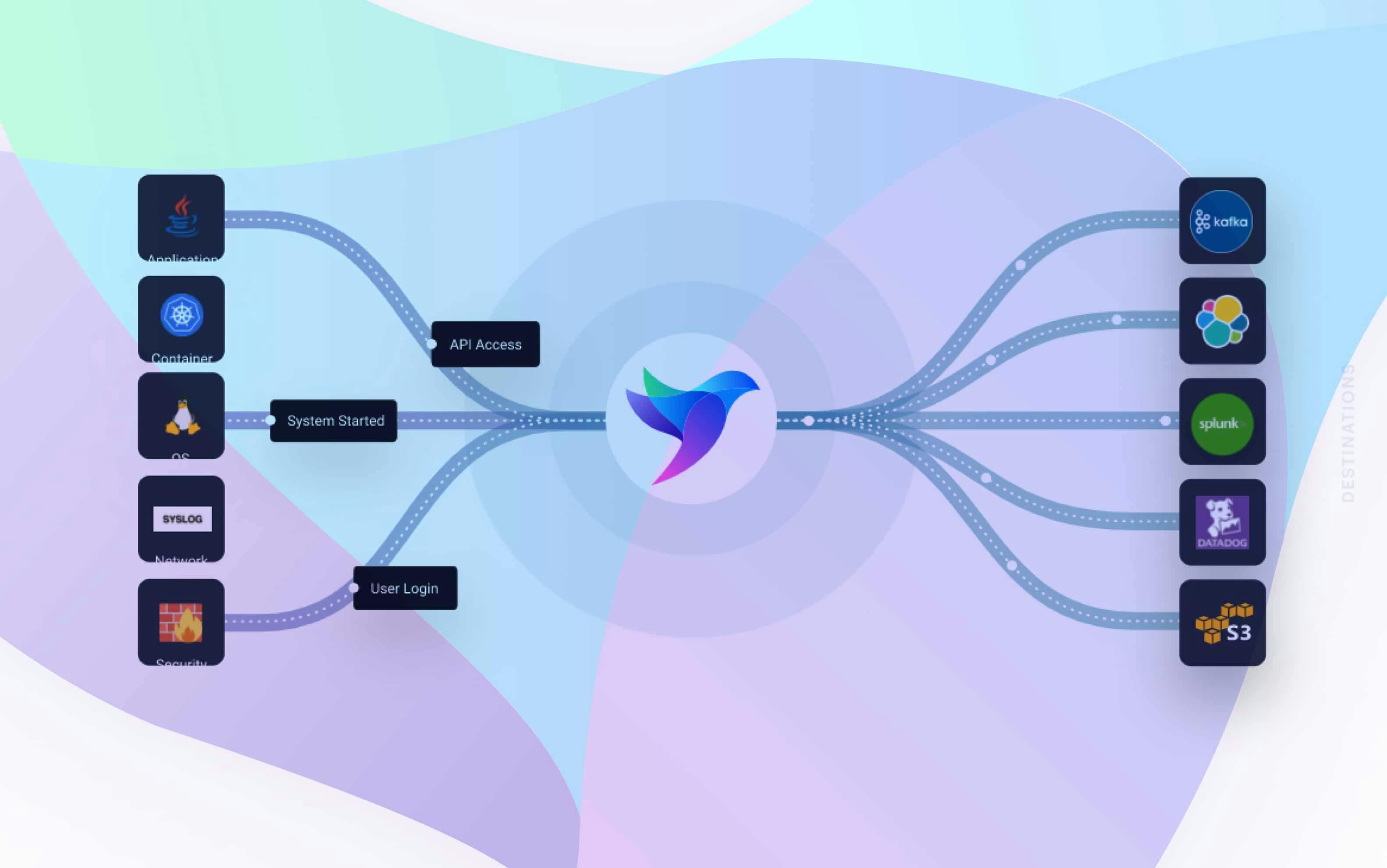
Calyptia is a first-mile data collection pipeline that unifies your data across Applications, Microservices, Infrastructure, Firewalls, and Network devices and lets you route messages to multiple backends like Splunk, Kafka, Elasticsearch, Datadog, S3, and more. Calyptia has processing, filtering, routing, enrichment, and parsing capabilities to dramatically reduce Splunk cost and increase the value of your data.
Calyptia is based on the Open Source project, Fluentd and Fluent Bit, which are both projects in the Cloud Native Computing Foundation.
Validate and filter your data
One of the simplest ways to reduce data sent to Splunk is by reducing the data you send. A simple way to do this without worrying about accidentally filtering out an important message is to remove messages with null content for important fields such as “message” or “log.” This is quite simple to do with Calyptia; you can use the included GREP filter and check if particular messages are null. An example of this configuration can be seen using Calyptia’s Config Builder.
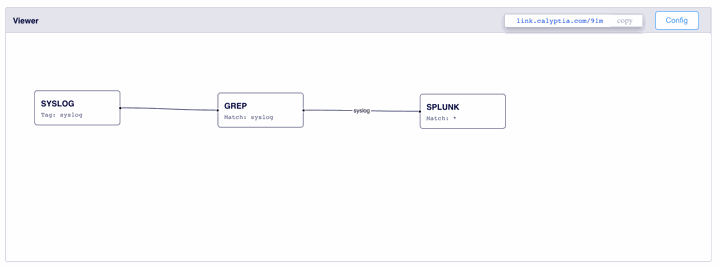
Configuration: https://link.calyptia.com/91m
Another simple way to reduce volume is by filtering your data based on certain attributes. One of the most common pains is a developer accidentally leaving a trace or debug logging on and discovering after 70% of the license is used. For example, if we deploy a Java application, we can use the same GREP filter from before, and this time search message content for the term `debug` or `trace.` If they are found, we can easily exclude these messages from sending to Splunk.
[FILTER]
name grep
Match *
Exclude log *[DEBUG]*Calyptia also offers advanced routing, and if we want to, we could use the Re-write tag filter instead to route these to a lower-cost storage backend such as Snowflake or Amazon S3.
Aggregate logs before sending them
Many times log messages contain important information and metrics that you do not need to view at an individual message layer but over a period of time in aggregate. Calyptia’s SQL stream processor allows you to run functions before sending data off to Splunk. Some examples include:
Summary of errors encountered over 1000 messages.
Average, Max, Min of response time over 1000 messages
Time series prediction of a metric over a 100-second window
Aggregating over thousands of messages per second can save you tons on storage while still allowing you to gain insights into Splunk’s visualizations and dashboards. With the first example, aggregating over 1000 messages per second down to 1 message per second can reduce log volume by 99.9%!
An example Calyptia SQL Aggregation on top of Nginx logs
[STREAM_TASK]
Name http_200_code
Exec CREATE STREAM http200 WITH (tag='http200') AS SELECT * FROM TAG:'nginx' WHERE code='200';Send what matters with context.
While most vendors might push for you to segregate your data by certain key messages, sometimes missing context can lead to even longer debug times – which nullifies any cost efficiencies the system is trying to deliver.
[STREAM_TASK]
Name http_404 snapshot
Exec CREATE SNAPSHOT log_snapshot WITH (seconds='5', tag='nginx') AS SELECT * FROM STREAM:nginx WHERE code='500'Thankfully, Calyptia includes a SQL stream processor that can search for specific content and, upon encountering, can send contextual messages around it to make debugging easier. This allows you to keep sending data to multiple backends such as Splunk and S3, without having to worry that you will miss context by only sending errors to Splunk.
How do I get started?
You can start by signing up for our free Calyptia Cloud, and get started building out configuration in our Config Builder.
You might also like

Observability Day at Kubecon + CloudNativeCon North America 2023
Calyptia is proud to sponsor Observability Day, a co-located event during Kubecon + CloudNativeCon North America 2023 to be held on November 6, 2023, in Chicago, IL.