
Kubernetes Metadata Enrichment with Fluent Bit (with Troubleshooting Tips)
Kubernetes Metadata Enrichment with Fluent Bit (with Troubleshooting Tips)
When run in Kubernetes (K8s) as a daemonset, Fluent Bit can ingest Kubelet logs and enrich them with additional metadata from the Kubernetes API server. This includes any annotations or labels on the pod and information about the namespace, pod, and the container the log is from. It is very simple to do, and, in fact, it is also the default setup when deploying Fluent Bit via the helm chart.
The documentation goes into the full details of what metadata are available and how to configure the Fluent Bit Kubernetes filter plugin to gather them. This post primarily gives an overview of how the filter works and provides common troubleshooting tips, particularly with issues caused by misconfiguration.
How to get Kubernetes metadata?
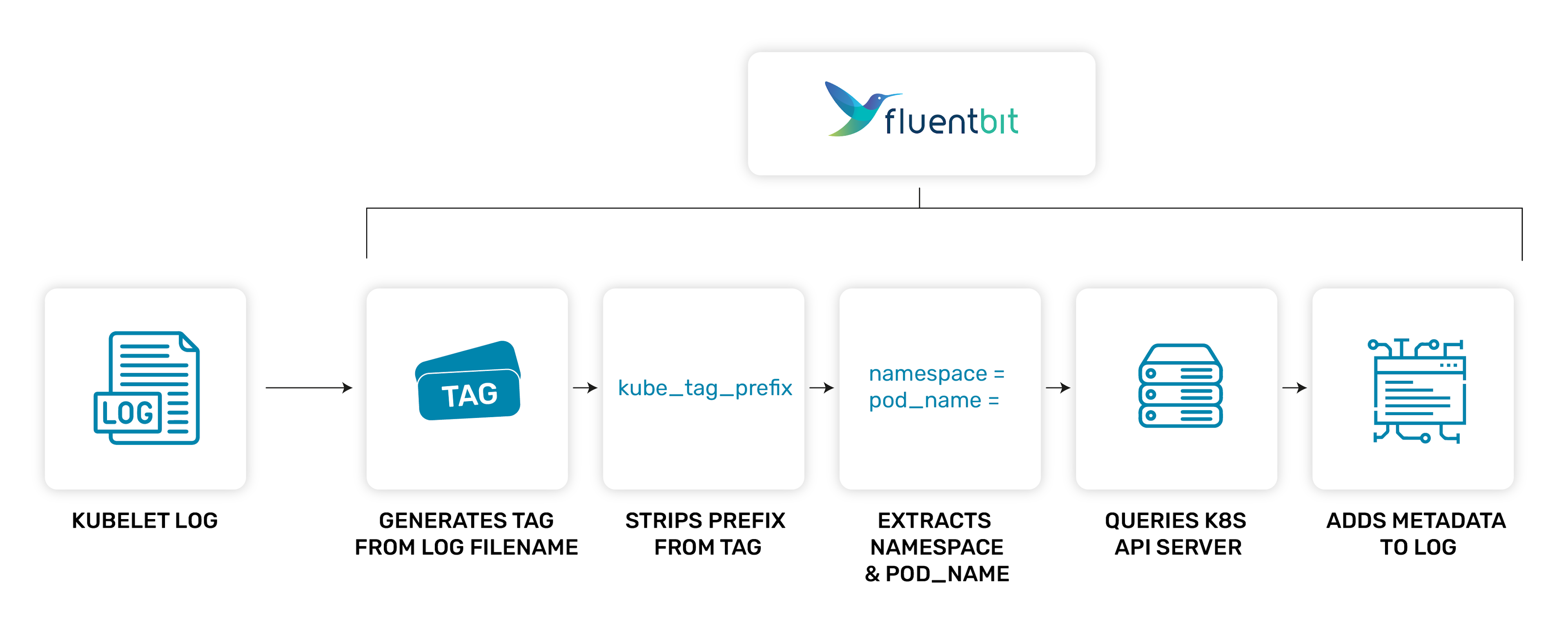
Let us take a step back and look at what information is required to query the K8s API server for metadata about a particular pod. We need two things:
Namespace
Pod name
Cunningly, the Kubelet logs on the node have to provide this information in their filename by design. This information enables Fluent Bit to query the K8s API server when all it has is the log file. Therefore, given a pod log file(name), we should be able to query the K8s API server for the rest of the metadata describing the pod.
Using Fluent Bit to enrich the logs
First off, we need the actual logs from the Kubelet. This is typically done by using a daemonset to ensure a Fluent Bit pod runs on every node and then mounts the Kubelet logs from the node into the pod.
Now that we have the log files themselves we should be able to extract enough information to query the K8s API server. We do this with a default setup using the tail plugin to read the log files and inject the filename into the tag:
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
multiline.parser docker, criWildcards in the tag are handled in a special way for the tag filter. This configuration will inject the full path and filename for the log file into the tag after the kube. prefix.
Once the kubernetes filter receives these records, it parses the tag to extract the information required. To do so, it needs the kube_tag_prefix value to strip off any redundant tag or path to leave just the log filename with the three things required to query the K8s API server. Using the defaults would look like this:
[FILTER]
Name kubernetes
Match kube.*
Kube_Tag_Prefix kube.var.log.containers.Fluent Bit inserts the extra metadata from the K8s API server under the top-level kubernetes key.
Using an example, we can see how this flows through the system.
Log file:
/var/log/container/apache-logs-annotated_default_apache-aeeccc7a9f00f6e4e066aeff0434cf80621215071f1b20a51e8340aa7c35eac6.log
Gives us a tag like so (slashes are replaced with dots):
kube.var.log.containers.apache-logs-annotated_default_apache-aeeccc7a9f00f6e4e066aeff0434cf80621215071f1b20a51e8340aa7c35eac6.log
We then strip of kube_tag_prefix:
apache-logs-annotated_default_apache-aeeccc7a9f00f6e4e066aeff0434cf80621215071f1b20a51e8340aa7c35eac6.log
Now we can extract the relevant fields with a regex:
(?<pod_name>[a-z0-9](?:[-a-z0-9]*[a-z0-9])?(?:\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)-(?<container_id>[a-z0-9]{64})\.log$
pod_name = apache-logs-annotated
namespace = default
container_name = apache
container_id = aeeccc7a9f00f6e4e066aeff0434cf80621215071f1b20a51e8340aa7c35eac6
Misconfiguration woes
There are a few common errors that we frequently see in community channels:
Mismatched configuration of tags and prefix
Invalid RBAC/unauthorised
Dangling symlinks for pod logs
Caching affecting dynamic labels
Incorrect parsers
Mismatched tag and tag prefix
The most common problems occur when the default tag is changed for the tail input plugin or when a different path is used for the logs. When this happens, the kube_tag_prefix must also be changed to ensure it strips everything off except the filename.
The kubernetes filter will otherwise end up with a garbage filename that it either complains about immediately or it injects invalid data into the request to the K8s API server. In either case, the filter will not enrich the log record as it has no additional data to add.
Typically, you will see a warning message in the log if the tag is obviously wrong, or with log_level debug, you can see the requests to the K8s API server with invalid pod name or namespace plus the response indicating there is no such pod.
$ kubectl logs fluent-bit-cs6sg
…
[2023/11/30 10:08:14] [debug] [filter:kubernetes:kubernetes.0] Send out request to API Server for pods information
[2023/11/30 10:08:14] [debug] [http_client] not using http_proxy for header
[2023/11/30 10:08:14] [debug] [http_client] server kubernetes.default.svc:443 will close connection #60
[2023/11/30 10:08:14] [debug] [filter:kubernetes:kubernetes.0] Request (ns=default, pod=s.fluent-bit-cs6sg) http_do=0, HTTP Status: 404
[2023/11/30 10:08:14] [debug] [filter:kubernetes:kubernetes.0] HTTP response
{"kind":"Status","apiVersion":"v1","metadata":{},"status":"Failure","message":"pods \"s.fluent-bit-cs6sg\" not found","reason":"NotFound","details":{"name":"s.fluent-bit-cs6sg","kind":"pods"},"code":404}This example was created using a configuration file like below for the official helm chart. As you can see we have added two characters to the default tag prefix (my) and you can see above in the details for the error that the name of the pod has two extra characters in the prefix: it should be fluent-bit-cs6sg but is s.fluent-bit-cs6sg, no such pod exists so it reports a failure. Without log_level debug you just get no metadata.
config:
service: |
[SERVICE]
Daemon Off
Log_Level debug
inputs: |
[INPUT]
Name tail
Path /var/log/containers/*.log
multiline.parser docker, cri
Tag mykube.*
Mem_Buf_Limit 5MB
Skip_Long_Lines On
filters: |
[FILTER]
Name kubernetes
Match *Unexpected tags
Using wildcards in the tail input plugin can trip you up sometimes: the * wildcard is replaced by the full path of the file but with any special characters (e.g. /) replaced with dots (.).
Beware of modifying the default kube.* tag in this case, and — as I try to stress as much as possible — use stdout to see the actual tags you are getting if you have any issues. As an example, consider the following tail configuration:
[INPUT]
Name tail
Path /var/log/containers/*.logNow, you will get tags that look like this depending on what you configure:
Tag kube.* ⇒ kube.var.log.containers.<filename>
Tag kube_* ⇒ kube_.var.log.containers.<filename>
In the second case, notice that we have an underscore followed by a dot. Whereas, in the first case, there is no double dot as it is automatically collapsed by the input plugin. This can mean your filters do not match later on and can cause confusing problems. The first step is always the trusty stdout output, though, to verify.
Invalid RBAC
The Fluent Bit pod must have the relevant roles added to its service account that allow it to query the K8s API for the information it needs. Unfortunately, this error is typically just reported as a connectivity warning to the K8s API server, so it can be easily missed.
To troubleshoot this issue, use log_level debug to see the response from the K8s API server. The message will basically say “missing permissions to do X” or something similar and then it is obvious what is wrong.
[2022/12/08 15:53:38] [ info] [filter:kubernetes:kubernetes.0] testing connectivity with API server...
[2022/12/08 15:53:38] [debug] [filter:kubernetes:kubernetes.0] Send out request to API Server for pods information
[2022/12/08 15:53:38] [debug] [http_client] not using http_proxy for header
[2022/12/08 15:53:38] [debug] [http_client] server kubernetes.default.svc:443 will close connection #23
[2022/12/08 15:53:38] [debug] [filter:kubernetes:kubernetes.0] Request (ns=default, pod=calyptia-cluster-logging-316c-dcr7d) http_do=0, HTTP Status: 403
[2022/12/08 15:53:38] [debug] [filter:kubernetes:kubernetes.0] HTTP response
{"kind":"Status","apiVersion":"v1","metadata":{},"status":"Failure","message":"pods \"calyptia-cluster-logging-316c-dcr7d\" is forbidden: User \"system:serviceaccount:default:default\" cannot get resource \"pods\" in API group \"\" in the namespace \"default\"","reason":"Forbidden","details":{"name":"calyptia-cluster-logging-316c-dcr7d","kind":"pods"},"code":403}
[2022/12/08 15:53:38] [ warn] [filter:kubernetes:kubernetes.0] could not get meta for POD calyptia-cluster-logging-316c-dcr7dIn the example above you can see without log_level debug all you will get is the warning message:
[2022/12/08 15:53:38] [ info] [filter:kubernetes:kubernetes.0] testing connectivity with API server...
[2022/12/08 15:53:38] [ warn] [filter:kubernetes:kubernetes.0] could not get meta for POD calyptia-cluster-logging-316c-dcr7dDangling symlinks
Kubernetes has evolved over the years, and new container runtimes have also come along. As a result, the filename requirements for Kubelet logs may be handled using a symlink from a correctly named pod log file to the actual container log file created by the container runtime. When mounting the pod logs into your container, ensure they are not dangling links and that their destination is also correctly mounted.
Caching
Fluent Bit caches the response from the K8s API server to prevent rate limiting or overloading the server. As a result, if annotations or labels are applied or removed dynamically, then those changes will not be seen until the next time the cache is refreshed. A simple test is just to roll/delete the pod so a fresh one is deployed and check if it picks up the changes.
Log file parsing
Another common misconfiguration is using custom container runtime parsers in the tail input. This problem is generally a legacy issue as previously there were no inbuilt CRI or docker multiline parsers. The current recommendation is always to configure the tail input using the provided parsers as per the documentation:
[INPUT]
name tail
path /var/log/containers/*.log
multiline.parser docker, criDo not use your own CRI or docker parsers, as they must cope with merging partial lines (identified with a P instead of an F).
The parsers for the tail plugin are not applied sequentially but are mutually exclusive, with the first one matching being applied. The goal is to handle multiline logs created by the Kubelet itself. Later, you can have another filter to handle multiline parsing of the application logs themselves after they have been reconstructed here.
What’s Next?
Join the Fluent Slack Community: To learn more about Fluent Bit, we recommend joining the Fluent Community Slack channel where you will find thousands of other Fluent Bit users.
Check Out Fluent & Calyptia On-Demand Webinars: Our free on-demand webinars that range from introductory sessions to deep dives into advanced features.
Learn about Calyptia Core: Finally, you may also be interested in learning about our enterprise offering, Calyptia Core, which simplifies the creation and management of telemetry data pipelines at scale. Request a customized demo or sign up for a free trial now.
You might also like

Statement on CVE-2024-4323 and its fix
We'd like to make sure you’re aware of a security vulnerability (known as CVE-2024-4323) that impacts Fluent Bit versions 2.0.7 through 3.0.3. The latest version of Fluent Bit, version 3.0.4, fixes this issue.
